
 本著作係採用創用 CC 姓名標示-相同方式分享 4.0 國際授權條款授權.
本著作係採用創用 CC 姓名標示-相同方式分享 4.0 國際授權條款授權.
本文原刊於 2022-11-30《藝術松No.3:關於Web3》
作者:
- 李承錱(中央研究院,資訊科學研究所|研究資料寄存所1)
- 何明諠(中央研究院,資訊科技創新研究中心|研究資料寄存所)
- 王家薰(中央研究院,資訊科學研究所|研究資料寄存所)
語意網的哲學視角
奧地利哲學家維根斯坦 (Ludwig Wittgenstein) 在《哲學研究》(Philosophical Investigations) 中的開篇即指出,語言中的字詞命名了各物。命名使每個字詞都有相關聯的「意義」(meaning),某個字詞的意義,即來自它被用於指涉何物 (Wittgenstein, 1973)。維根斯坦所說的「物」(object),可以是客觀世界的物,但也能是存在於某人心中的所想。在此基礎上,語句的對錯僅在於其是否吻合某種既存的事態 (existing state of affairs) (Jahanforouz, 2019; Aaberge, 2013)。
維根斯坦對語言和意義的看法,挑戰了柏拉圖以降,認為事物有其真正的本質,而語句的對錯判準,在於其是否符應事物本質的理型論者想法,但也引出了私有語言 (private language) 或共通理解如何可能等相關問題。儘管持續存在爭議,但沿著維根斯坦對語言的理解,卻可用來掌握本文主題「語意網」(Semantic Web) 所打算處理的問題。
語意網並非近年才出現的新概念。在 1994 年,全球資訊網發明人 Tim Berners-Lee 在首次的全球資訊網研討會 (World Wide Web Conference) 上,以「網路對語意的需求」(The Need for Semantics in the Web)為題,提出了「語意網」的構想 (Berners-Lee, 1994)。
語意網的原始構想並不複雜。打造語意網,並非要打造另一個新的網路,而是要讓既有的網路資料,成為可被機器理解,亦即機器可讀 (machine-readable) 的資料。我們眾人所接觸的網頁,主要是以 HTML (HyperText Markup Language,超文本標記語言) 這套語法所撰寫。HTML 的主要功能,是透過一系列預先定義好的 HTML 標籤 (HTML tags),使不同機器能以相同形式,展示人類使用自然語言所撰寫的資訊,以方便另一群人閱讀、理解 (Cardoso, J.& Sheth, A. ,2006)。
儘管 HTML 標籤也可被視為是語意標籤2,但若只使用 HTML 標籤,對增進機器對語意的理解仍十分有限。例如在 HTML 的環境下,有個藝術品資料庫,其中某藝術品的館藏地標記為「松山」,機器通常無法理解所謂松山,究竟是指台灣的松山,亦或日本的松山;又或者有兩個資料庫,在作者的欄位,一個資料庫使用「artist」,另一個則是「creator」,若未經更多定義,機器也無法理解這是兩個相同的欄位名。
人類所以能克服自然語言的岐義,以理解另一個人的說話內容,主要仍是透過知識、脈絡的補充,使人們能固定彼此話語的意義,達成溝通 (Aaberge, 2013)。而在語意網技術未介入前,一台機器雖可在其自身展示很多資訊,但對另一台機器而言,大抵都像是模糊的語言,或甚至是無法理解的私有語言。在此意義上,網路過往所面臨的語意問題,和維根斯坦所遭遇的十分類似。
一個有趣的對照是,語意網中用以固定知識內涵的「知識本體」 (ontology) ——或稱「語彙 」(vocabularies) 3,若轉換到哲學領域,一般稱為「本體論」。在哲學上,本體論是探究事物本質 (nature) 的學問。僅由這個簡單的詞語對照,似乎就能理解,打造語意網的目標之一,是要使機器能確定網路上諸多資訊的本質意義。而語意網如何確定並傳達資訊的意義,則有賴本文以下將介紹的語意網技術。
打造語意網的技術
自全球資訊網 (World Wide Web; WWW) 於 1990 年問世以來,網路世界已有翻天覆地的改變。2004 年起,以參與式網路 (participative web) 與社群網路 (social web) 為核心的 Web 2.0,其以使用者為中心的互動式即時體驗,形塑了今日的網路世界。而對於次世代網路的想像,Tim Berners-Lee 於 2006 年的訪談中首次提及 Web 3.0,並認為 Web 3.0 將是一個匯集了大量資料的「語意網 」(Semantic Web) (Shannon, 2006)。
「語意網」這個概念,在 1994 年就已被發想,並於 1998 被正式提出 (Berners-Lee, 1998)。簡單來說,語意網即「資料的網絡」(web of data) (W3C, 2015)。「資料」是指於網路上流通的各式資訊,舉凡近期上映的電影情報、私房景點地圖、部落格文章等,皆屬資料的範疇。語意網的目標,在於以通用的標準格式,將這些資料描述成為一個個「資源」(resource),而此標準格式即為「資源描述架構」(Resource Description Framework; RDF)。
在語意網中,任何概念均可使用 RDF 敘述 (statement) 加以描述。一個使用 RDF 資料模型 (data model) 的敘述,是由主詞 (subject)、述詞 (predicate) 與受詞 (object) 三個元素組成,又稱「三元組」(triple)。主詞與受詞為欲描述關係的兩個對象,述詞則說明兩者之間的關係。以下方這個敘述為例:
「陳澄波是一位畫家。」
在文法中,「陳澄波」、「是一位」、「畫家」即是一標準的主詞–動詞–受詞 (Subject–Verb–Object) 語序,對應到 RDF 敘述即為主詞–述詞–受詞 (Subject–Predicate–Object)。我們可將前述關係以圖 (Graph) 的形式呈現,如圖一。

RDF 並未規範單一的語法格式,包括 RDF/XML、Turtle 與 JSON-LD 等串列化格式 (serialization formats) 均可用來撰寫 RDF 敘述 (W3C Working Group, 2014)。以 RDF/XML 為例,我們可將例句以 <Subject> <Predicate> <Object> 的格式,描述為由三個「資源」組成的三元組。為便於唯一識別與相互連結,三元組的資源通常以國際化資源識別碼 (Internationalized Resource Identifier; IRI) 表示:
<https://www.wikidata.org/entity/Q707301> <https://schema.org/hasOccupation> <https://dbpedia.org/ontology/Painter> .
其中,<https://www.wikidata.org/entity/Q707301> 指稱陳澄波此人;<https://schema.org/hasOccupation> 用來描述一個人的職業;<https://dbpedia.org/ontology/Painter> 則指稱畫家。
而根據資源的內涵,可再將其區分為「類別」 (Classes)、「屬性」 (Properties) 與「個體 」(Individuals) 三種類型,並由各領域內公認的「語彙」(vocabularies) 所定義。語彙由 RDF Schema 或更為完整的網路本體語言 (Web Ontology Language; OWL) 定義,同樣以 IRI 方式呈現,並共用相同的命名空間前綴 (namespace prefixes),供程式快速解析。
例如在上述例子中,<https://schema.org/hasOccupation> 即為「屬性」類型的資源(描述「職業」此一屬性),並取自 <https://schema.org/> 這個命名空間前綴,擁有該命名空間的語彙名稱則(正好)是 Schema.org,此語彙專門用於描述網路上的各類資訊;<https://dbpedia.org/ontology/Painter> 則為「類別」類型的資源(描述「畫家」此一分類),而 <https://dbpedia.org/ontology/> 為結構化資料庫 DBpedia 所使用的知識本體,因其多元的資料內容,而廣為其他網路資源所使用;至於 <https://www.wikidata.org/entity/Q707301> 就屬「個體」類型的資源(「陳澄波」此人)。
以 RDF 格式建立,使用語彙描述,彼此相互關聯,且可使用語意網工具——如使用 SPARQL 查詢、或以 SHACL (Shapes Constraint Language) 進行條件驗證等——操作的資源集合,稱為「資料連結」(Linked Data)4。資料連結所形成的網絡,即語意網「資料的網絡」精神的技術實踐。前面提及的 RDF、OWL、SPARQL,與 SHACL 等規範,均為發展全球資訊網的主要國際組織 W3C 的推薦標準 (W3C Recommendation),代表這些技術已經過 W3C 成員的充分討論與實證,並推薦廣泛應用於網際網路。
誰才是 Web 3.0:語意網或其他
如同 Web 2.0,Web 3.0 並無一致定義,且隨技術發展而不斷演變。例如,紐約時報科技記者 John Markoff 即認為 Web 3.0 將是語意網與人工智慧 (AI) 的結合 (Markoff, 2006);Web 3.0 有時也會與 Web3(由以太坊共同創辦人 Gavin Wood 於 2014 年提出)一併提及,而後者的目標為建立「以區塊鏈為基礎的去中心化網路」 (Edelman, 2021),其內涵與關注議題,均與語意網不同;有趣的是,亦有將語意網與去中心化網路均視為 Web 3.0 特徵的觀點 (Bansgopaul, 2021; Zarrin, Wen Phang, Babu Saheer, & Zarrin, 2021)。但無論是將語意網作為網際網路資料的主體,或是將語意網視為既有資料的補充 (Antoniou & Van Harmelen, 2008),語意網相關技術將資料以結構化形式儲存與呈現,在資料交換、資訊檢索、知識管理、物聯網等領域均有助益 (Patel & Jain, 2021)。
然而,相較於問世以來即迅速發展且影響深遠的 Web 2.0,以及迅速竄紅的 Web3,被稱為 Web 3.0 且賦予甚高期待的語意網,仍不慍不火。究其原因,首先,語意網不若 Web 2.0,一般網路使用者並不直接參與 RDF 資源的生產活動。為求內容的權威性,資源的類別、屬性、關係的選定,涉及領域專業;資源的產製,亦仰賴電腦科學的相關技術,使過往語意網的應用侷限於專業社群。近年來,隨著以語意網技術為基底的維基資料5 (Wikidata; https://www.wikidata.org/) 提供 RDF 網頁編輯介面與視覺化搜尋服務 Query Service,以及 Google 搜尋引擎最佳化指標納入結構化資料描述 (Google, 2022) 後,語意網的技術可近性已有所改善。
再者,語意網資源的建立,需在既有的 HTML 網頁之外,再以 RDF 描述資料內容,甚至須考慮多語系內容,這均形成資料生產者與儲存空間的額外負擔;縱使網站經營者有意願產生機器可讀的資料,也更傾向直接使用網站既有的資料庫綱要 (database schema),透過 Web API 形式,提供 JSON 格式的資料,省去 RDF 描述的工夫,這些都造成 RDF 資源成長緩慢;缺乏 RDF 資源,也令資料連結無法發揮其「萬物相連」的綜效。但近期,在自然語言處理或機器學習技術的輔助下,自動生成 RDF 資源已成為可能。例如美國的大都會藝術博物館 (The Met) 即運用機器學習辨識藏品特徵,並將結果匯入 Wikidata (Lih, 2019);此外,保存龐大資料且具備領域知識的 GLAM——即美術館 (Galleries)、圖書館 (Libraries)、檔案館 (Archives) 及博物館 (Museums) 的聯合簡稱——為有效管理數位化的典藏品資訊,亦積極導入資料連結技術,如今歐洲數位圖書館 (Europeana)6、美國數位公共圖書館 (Digital Public Library of America; DPLA)7 等計畫已貢獻數以百萬計的 RDF 資源。
語意網技術在藝術上的應用
如前所述,近年來語意網的實作案例倍增。透過 RDF 架構描述資料內容,連接資料與資料的關係,就如同人類的腦神經網絡,從理解資料到串連資訊進而產生知識與邏輯概念的判斷。語意網透過知識本體,使人類與機器能以結構化的方式梳理既有的知識與文化,進而發掘更多隱藏其中的價值。
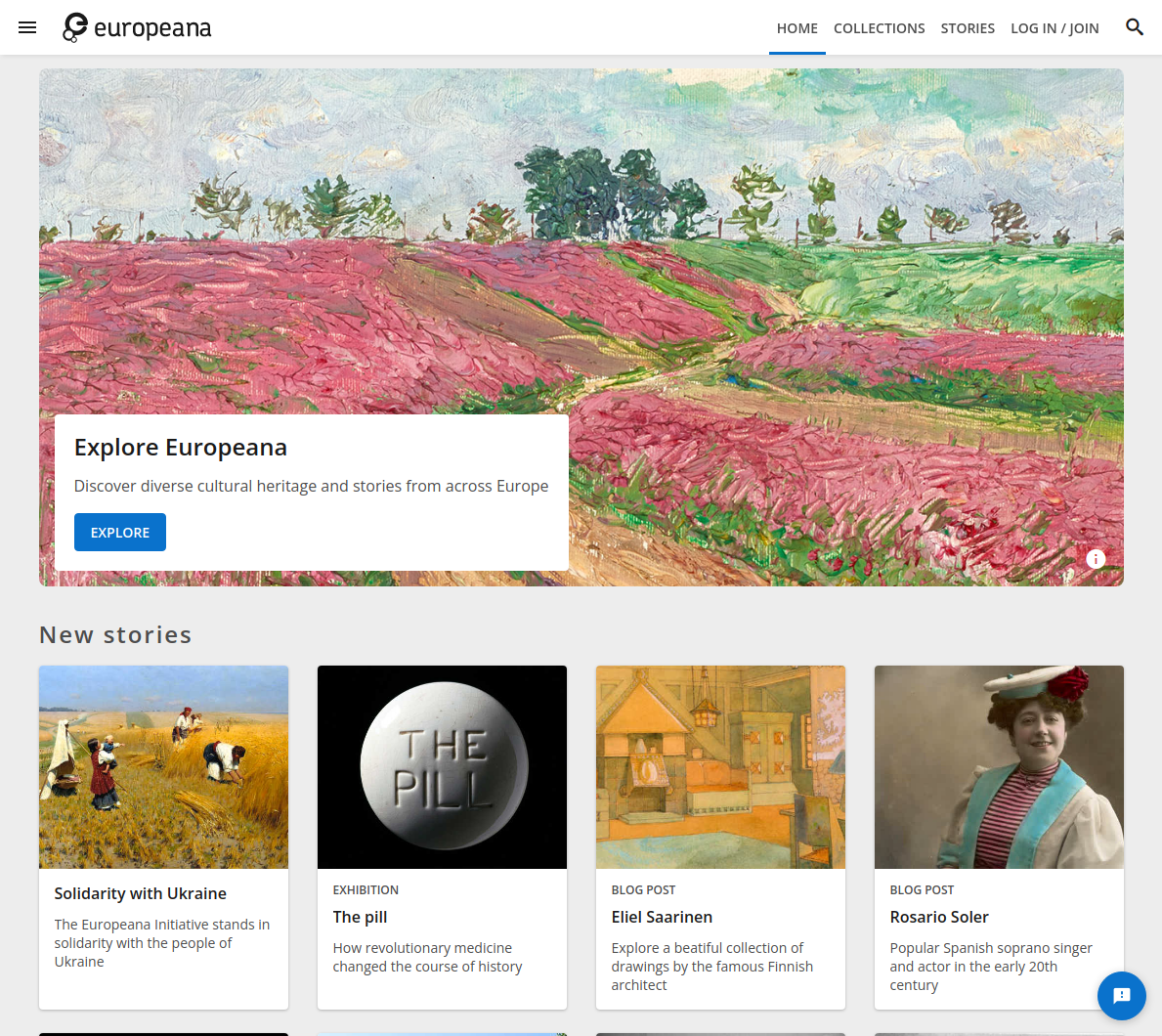
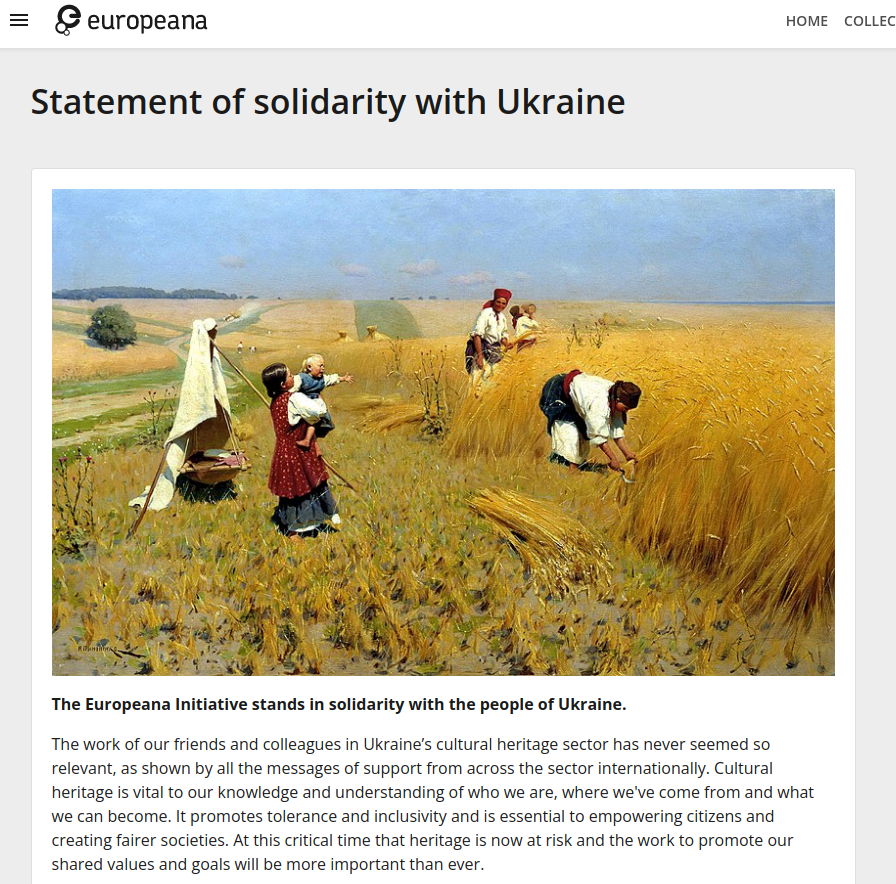
語意網技術在 GLAM 已盛行多年8,並特別對文化遺產 (Cultural Heritage) 的數位保存起到重大貢獻。如歐洲數位圖書館 (Europeana) 計畫 ,整合了歐盟境內超過 3,700 個不同機構,共 5,000 萬筆以上的藝術、報紙、考古、時尚、科學、體育、書籍、音樂和影片等各類文化遺產素材,並將這些素材供所有人自由的取用及分享。與過往的作法不同,Europeana 並不是將這些資料悉數儲存在集中的伺服器內,而是透過共同的資料格式如 EDM (the Europeana Data Model)9 及 Web API 進行資料的連接整合。令人訝異的是,歐盟早在 2005 年就發起這項計畫,其使用語意網技術,保存歐洲重要歷史與文化的作法,創造了語意網與整個數位文化遺產保存的雙贏局面。面對近期的烏克蘭與俄羅斯戰爭,Europeana 也正以同樣的技術,向使用者說明烏克蘭的文化歷史10,如圖二。
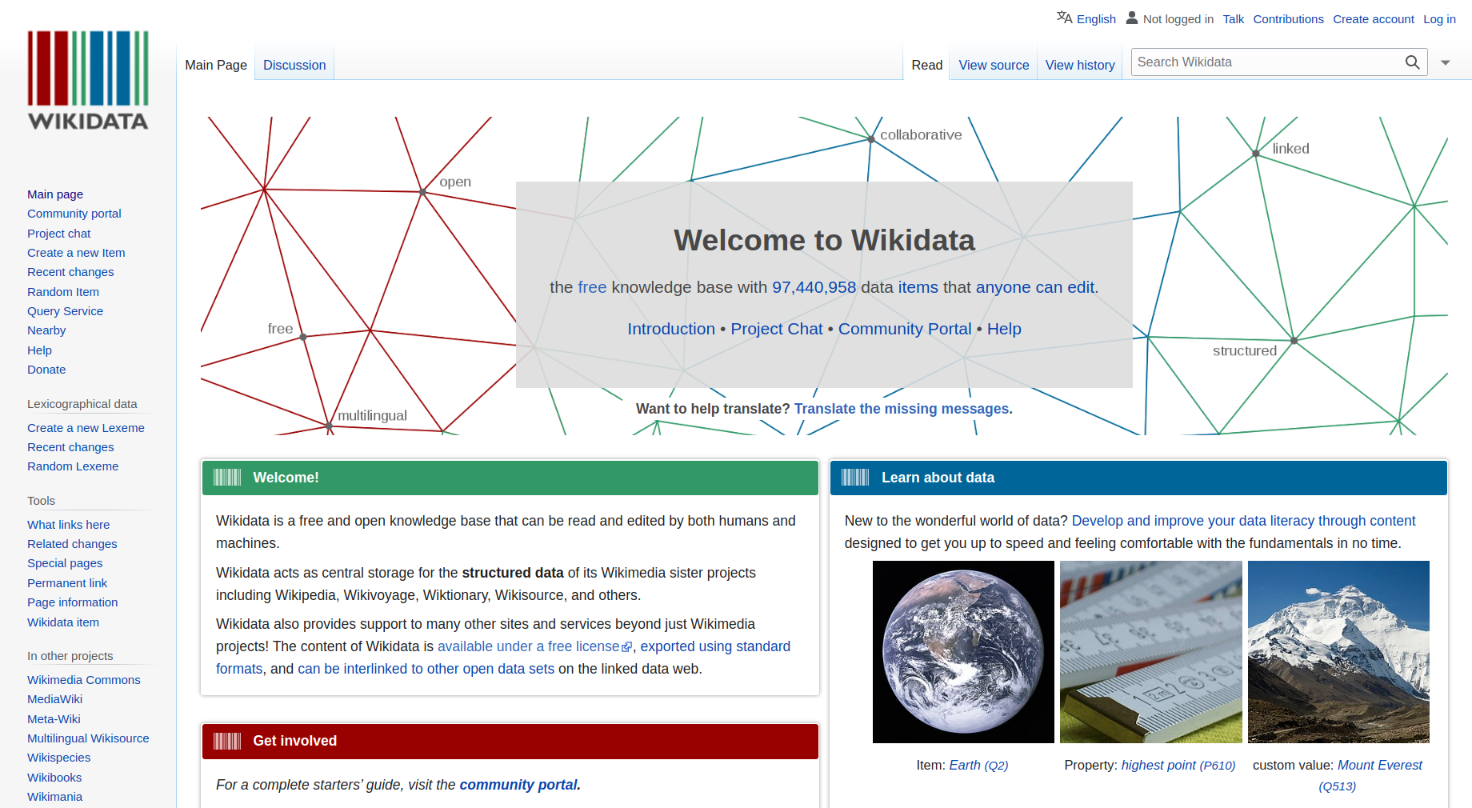
除了政府官方單位的支持與參與外,近年來亦有以群眾力量累積 RDF 資料量的案例,Wikidata 是其中廣為人知的專案。Wikidata 是一個可協同編輯的知識庫,它的重要任務之一,是將所有人類的知識,以知識本體進行以多語言的結構化處理,再以 CC0 這類無著作權的方式釋出。目前 Wikidata 已收錄了近 9 千萬筆的資料條目,且仍在快速增長中11。國際上的各博物館或研究單位(如 NASA)等權威性的組織單位,亦不斷聲援並支持這項工作。
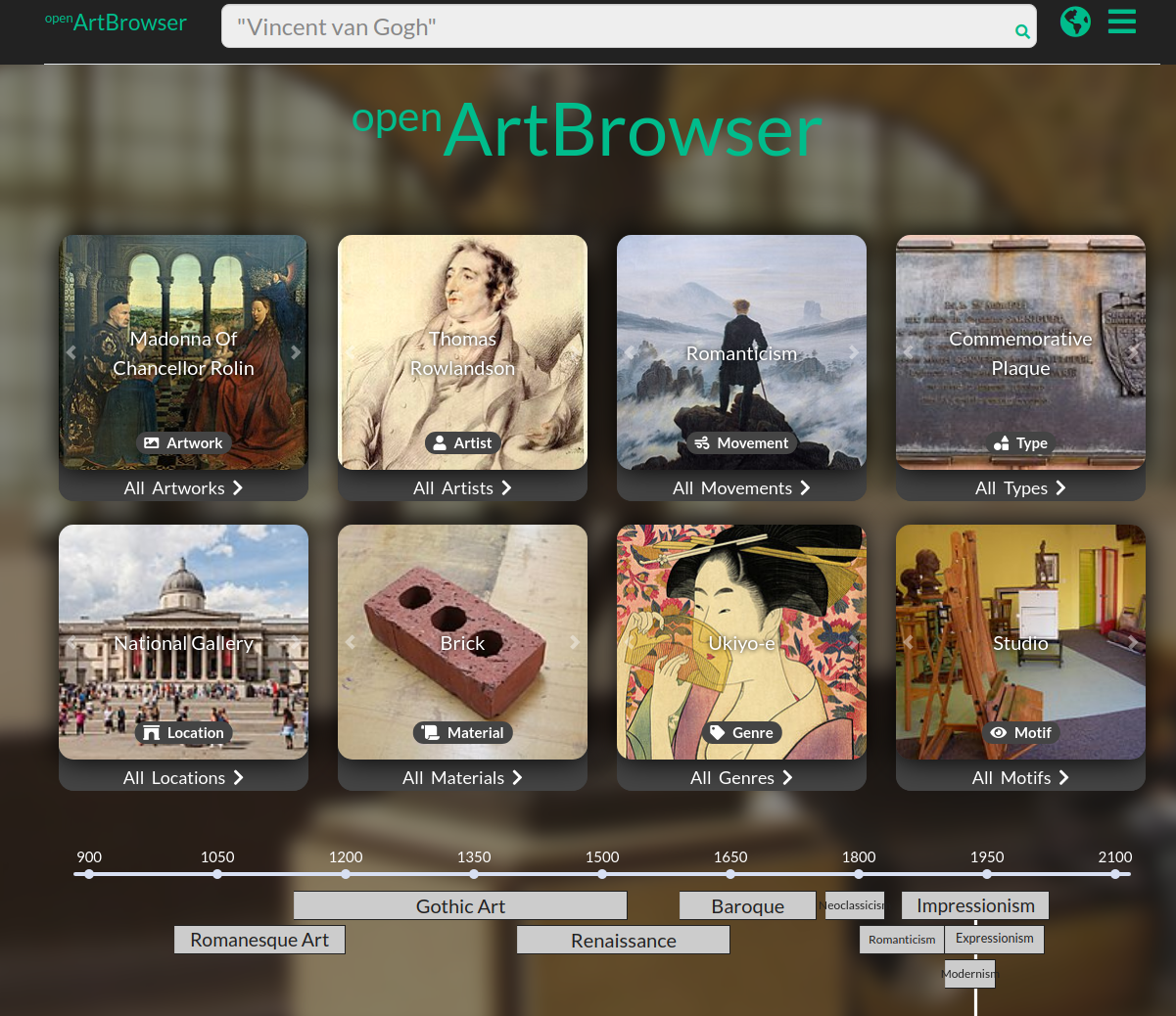
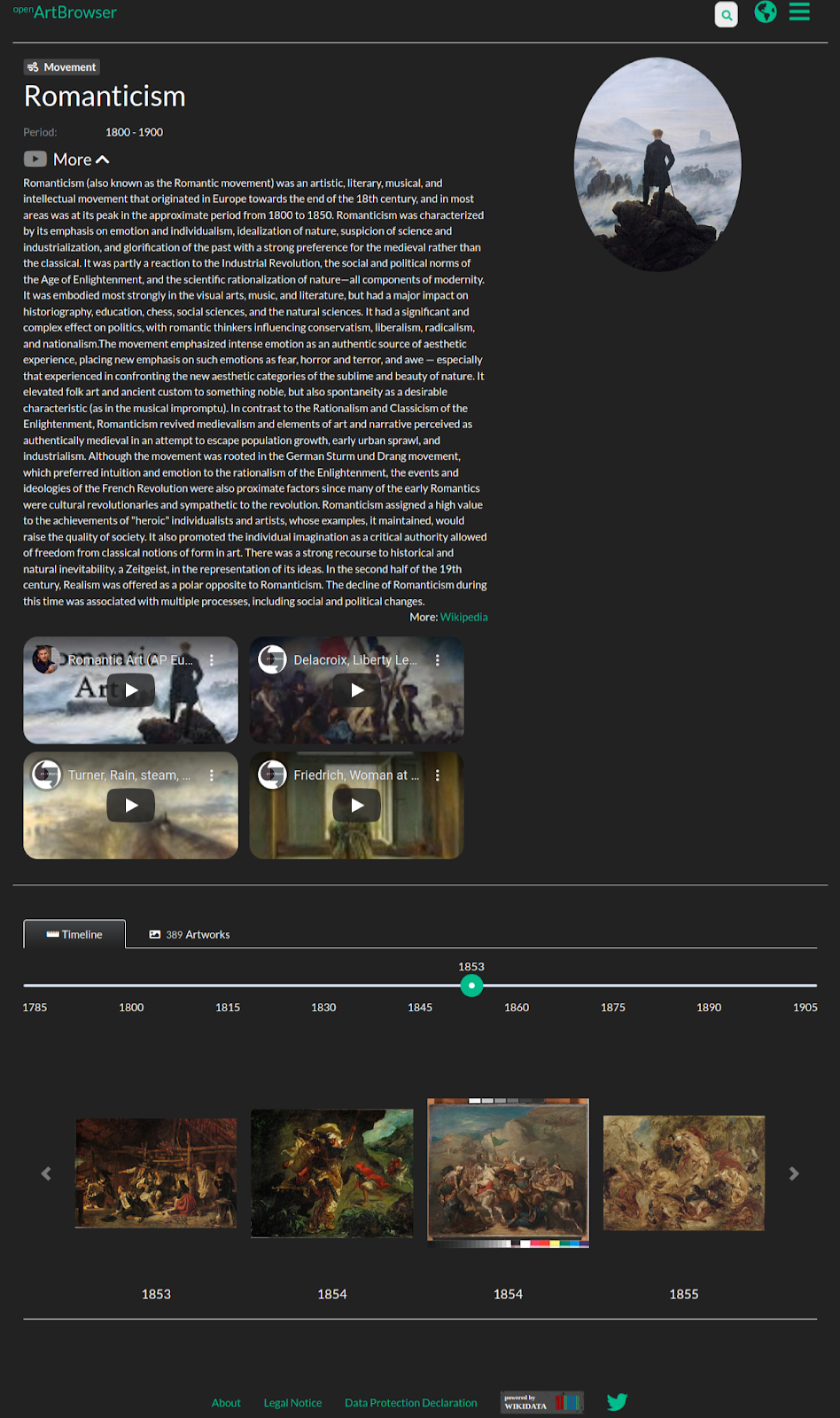
Wikidata 平台所整理的資料亦延伸出不少有趣的藝術專案,openArtBrowser12 是其中之一。openArtBrowser 收錄了古今 3 萬多位藝術家的作品(如下圖四),並運用 Wikidata 的條目,註記了藝術家及作品的相關後設資料 (Metadata),包含藝術家的性別、生存年代、國籍,藝術作品的風格、材料、創作時間地點等資訊。如此做的好處,一來是使用者能便利地在 openArtBrowser 上自由研究,若有使用者想了解某個藝術家,例如藝術家 Eliseu Visconti13,她可以瀏覽 openArtBrowser 中關於該藝術家的頁面,就藝術家的各時期、各屬性的作品進行比較,從不同視角體認藝術家的畫作風格及想法;或者她也能宏觀地就某個時期(如下圖五的浪漫主義時期14)的作品去做更大規模的比較。二來是如此標記的作品,未來也容易在維持一定的資料品質下,與其他平台進行串接。
語意網的世界到了嗎?
本文在前述篇幅,介紹了語意網的緣起、技術,以及應用案例,其中也提及了部份語意網技術在過去的缺陷。事實上,語意網從提出後,就不斷面臨各種大小質疑與批評。例如牛津大學的 Luciano Floridi,曾在 2009 年對語意網作出嚴厲且系統化的抨擊。他認為 Tim Berners-Lee 想連結網路上資料的構想,儘管願景宏大,卻是個受到過度吹捧的概念。其批評主要基於幾個理由:(1) 語意網在許多概念上──例如何謂語意 (semantics)、意義 (meaning)、理解 (understanding) ──模糊不清 (2) 欠缺成熟 AI 的協助,打造語意網將耗費難以想像的資源 (3) 語意網技術雖在個別領域取得成功,但要推廣至整個網路,仍有極大落差 (4) 語意網技術嚴格要求描述物件的後設資料欄位的正確性,而一個物件又可能有相當多的描述方式,這將使創造與維護描述都變得異常艱辛 (Floridi, 2009)。
類似的理由,2014 年,一篇名為「語意網仍算一回事嗎?」的文章,更直白地指出,若要提昇資料附加價值,與其耗費大量心力打造語意網,倒不如專注於改善資料品質 (Rochkind, 2014)。該文章也引用當時的一篇評論15,該評論直截了當地斷言,「語意網」的原始概念「已宛如去年在路上被撞死的生物一般死去」(as dead as last year's roadkill),剩下的都是一些變形。
上述的批評至今都仍有其道理,且過往對語意網的批評聲也並不僅止於此。但如本文所說,同樣不可忽視的是,自 1994 年 Tim Berners-Lee 提出概念雛型後,至今這 20 多年來,人們為了統一資訊意義已建立許多標準,採用語意網技術的資料服務更日益增加;而機器學習或自動化的成熟,亦加速了語意網的實作進程。儘管如今有關 Web 3.0 的定義,多數都與區塊鍊實作有關,但若語意網正隨時間逐一克服過去的難題,則打造一個資料可交互操作的網路,可能已不如想像遙遠。語意網或許不一定會是近在眼前的 Web 3.0,但它仍可以是指向 Web 4.0 的願景。
註解
1. 研究資料寄存所 (depositar) 為中央研究院資訊科學研究所、資訊科技創新研究中心共同建置的線上開放研究資料儲存庫 (data repository),並獲得科技部的經費支持。所有人均可在研究資料寄存所上自由取用、存放研究資料。網址 : <https://data.depositar.io/> (2022 年 4 月 20 日檢索)。
2. W3C 認為 HTML 的標籤可傳達意義,但若細究,無疑仍是在資料的格式或結構的層次上進行,詳細可見 W3C 有關 HTML5 的參考文件:<https://dev.w3.org/html5/html-author/> (2022 年 4 月 20 日檢索)。
3. 較為正式且複雜的「語彙」一般會稱為「知識本體」,但兩者常交互使用。
4. 也譯作「鏈結資料」、「連結資料」。
5. 也譯作「維基數據」。
6. 歐洲數位圖書館,網址 : <https://pro.europeana.eu/page/linked-open-data> (2022 年4 月 20 日檢索)。
7. 美國數位公共圖書館,網址 : <https://pro.dp.la/developers/technologies>(2022 年 4 月 20 日檢索)。
8. 有關 GLAM 的介紹 : <https://zh.wikipedia.org/wiki/GLAM_(%E7%94%A2%E6%A5%AD)>(2022 年 4 月 20 日檢索)。
9. EUROPEANA DATA MODEL 的介紹參見 : <https://pro.europeana.eu/page/edm-documentation> (2022 年 4 月 20 日檢索)。
10. 參見 Europeana 聲援烏克蘭文化保存網頁 : <https://www.europeana.eu/en/statement-of-solidarity-with-ukraine>(2022 年 4 月 20 日檢索)。
11. 可見 Wikidata 首頁上方所顯示之資料:「人人都可以編輯的自由知識庫,目前已有 97,461,453 個項目。」網址 : <https://www.wikidata.org/wiki/Wikidata:Main_Page>(2022 年 4 月 21 日檢索)。
12. openArtBrowser 網頁 : <https://openartbrowser.org/en/>(2022 年 4 月 20 日檢索)。
13. 藝術家 Eliseu Visconti (Q2340277) 的作品時序及介紹網頁,可參見 : <https://openartbrowser.org/en/artist/Q2340277?tab=timeline> (2022 年 4 月 20 日檢索)。
14. Romanticism Movement openArtBrowser 網頁 : <https://openartbrowser.org/en/movement/Q37068?tab=timeline>(2022 年 4 月 20 日檢索)。
15. 評論可參見 : <https://news.ycombinator.com/item?id=8510401>(2022 年 4 月 20 日檢索)。
參考資料
- Aaberge, T. (2013). The Semantic Web in a philosophical perspective. Retrieved from http://wab.uib.no/ojs/index.php/agora-alws/article/view/2661/3046
- Antoniou, G., & Van Harmelen, F. (2008). A semantic Web primer (2nd ed.). Cambridge, Mass: MIT Press.
- Bansgopaul, N. (2021, September 15). What Is Web 3.0 and Why Should You Care? Retrieved from https://www.newsweek.com/what-web-30-why-should-youcare-1627250
- Berners-Lee, T. (1994). Plenary at WWW Geneva 94. Retrieved from https://www.w3.org/Talks/WWW94Tim/
- Berners-Lee, T. (1998, September). Semantic Web Road map. Retrieved from https://www.w3.org/DesignIssues/Semantic.html
- Cardoso, J., Sheth, A. (2006). The Semantic Web and Its Applications. In: Cardoso, J., Sheth, A.P. (eds) Semantic Web Services, Processes and Applications. Semantic Web and Beyond, vol 3. Springer, Boston, MA. https://doi.org/10.1007/978-0-387-34685-4_1
- Edelman, G. (2021, November 29). The Father of Web3 Wants You to Trust Less. Retrieved from https://www.wired.com/story/web3-gavin-wood-interview/
- Floridi, L. (2009). Web 2.0 vs. the Semantic Web: A Philosophical Assessment. Episteme, 6(1), 25-37. doi:10.3366/E174236000800052X
- Jahanforouz, S. (2019, February). Wittgenstein's concept of language. http://dx.doi.org/10.13140/RG.2.2.35572.40325
- Lih, A. (2019, March 4). Combining AI and Human Judgment to Build Knowledge about Art on a Global Scale. Retrieved from https://www.metmuseum.org/blogs/now-at-the-met/2019/wikipedia-art-and-ai
- Markoff, J. (2006, November 12). Entrepreneurs See a Web Guided by Common Sense. Retrieved from https://www.nytimes.com/2006/11/12/business/12web.html
- Patel, A., & Jain, S. (2021). Present and future of semantic web technologies: a research statement. International Journal of Computers and Applications, 43(5), 413-422. doi:10.1080/1206212X.2019.1570666
- Rochkind, J. (2014, October 28). Is the Semantic Web Still a Thing?. Bibliographic Wilderness. Accessed April 20, 2022. https://bibwild.wordpress.com/2014/10/28/is-the-semantic-web-still-a-thing/.
- Shannon, V. (2006, May 23). Next, a “more revolutionary” Web. Retrieved from https://web.archive.org/web/20060524013307/http://www.iht.com/articles/2006/05/23/business/web.php
- W3C. (2015). Semantic Web. Retrieved from https://www.w3.org/standards/semanticweb/
- W3C Working Group. (2014, June 24). RDF 1.1 Primer. Retrieved April 18, 2022, from https://www.w3.org/TR/rdf11-primer/
- Wittgenstein, L., & Anscombe, G. E. M. (1973). Philosophical Investigations (3rd Edition) (3rd ed.). Pearson.
- Zarrin, J., Wen Phang, H., Babu Saheer, L., & Zarrin, B. (2021). Blockchain for decentralization of internet: prospects, trends, and challenges. Cluster Computing, 24(4), 2841-2866. doi:10.1007/s10586-021-03301-8
- Google(2022年4月13日)。瞭解結構化資料的運作方式。上網日期:2022年4月18日,檢自:https://developers.google.com/search/docs/advanced/structured-data/intro-structured-dat