
文字/劉宜庭|編輯/何明諠、王家薰
空氣盒子 (AirBox) 創立於 2013 年,最初僅在臺灣設立 20 多個感測點位,由中央研究院資訊科學研究所的陳伶志研究員規劃設置,那時他是一項關於氣候變遷的永續主題計畫共同主持人之一。計畫結束後,陳研究員持續以參與式感測 (crowdsensing) 理念為號召,使用開源工具分享空氣盒子的 PM 2.5 即時量測資料,廣泛獲得社會的關注與支持,促使「空氣盒子」成為一個全民參與的研究計畫。
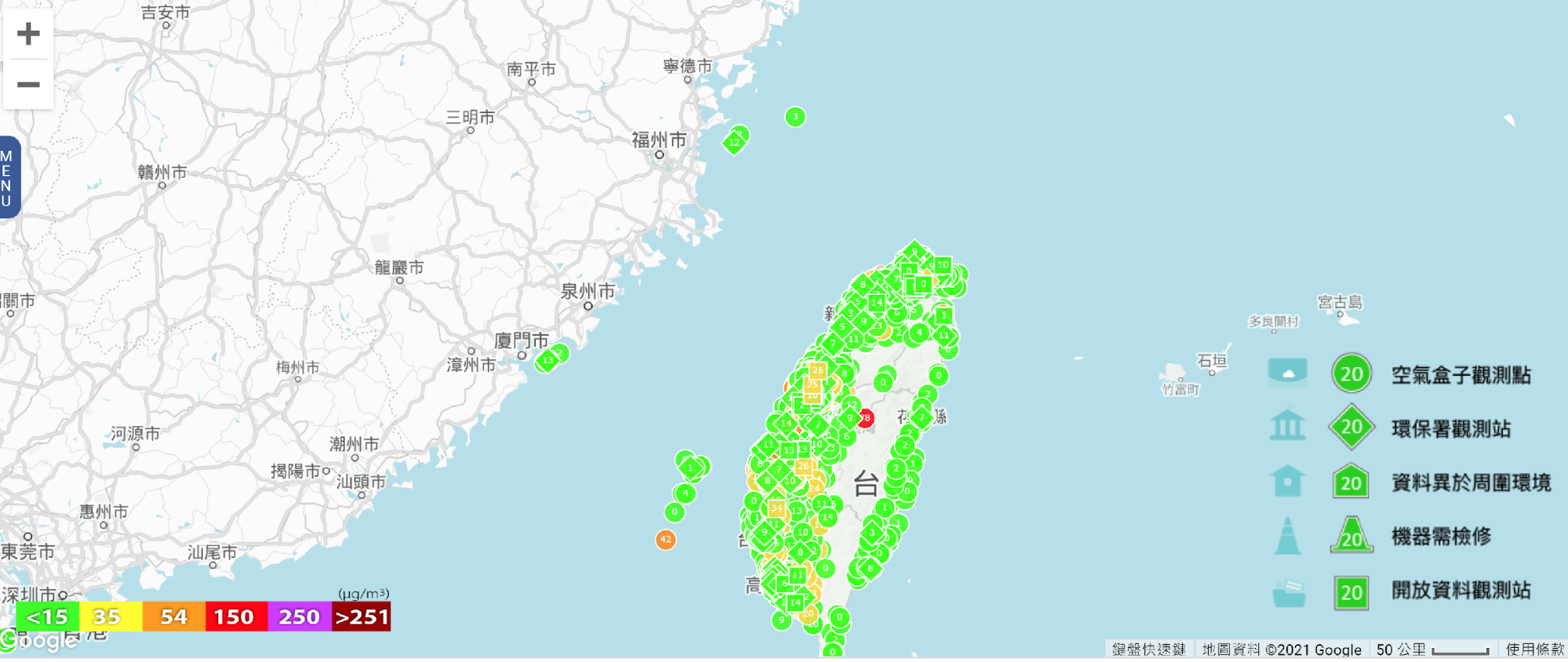
時至 2021 年,空氣盒子已安裝超過一萬台,其中約有 6000 台安裝在國內,4000 台安裝在國外。與此同時,空氣盒子每天蒐集全台灣超過 8 GB 的空氣品質監測資料,可用於即時校正的方式形成「全台 PM 2.5 分布地圖」,並以應用程式介面 (API) 方式提供資料。空氣盒子計畫在資料管理規劃 (data management planning) 的經驗值得借鏡,在「動態資料管理」(managing active data) 方面尤是。1
研究資料寄存所在 2021 年 4 月專訪陳伶志研究員。在訪談中,陳伶志回顧空氣盒子在研究資料管理上遭遇的困難,並建議各研究團隊及早針對研究資料的特性進行規劃。資料處理盡量自動化,分段處理整個研究資料釋出的流程;並應積極維護資料的「可取用性」(accessibility),方便其他研究者加入,讓研究資料的生產與使用形成一個良善的循環。
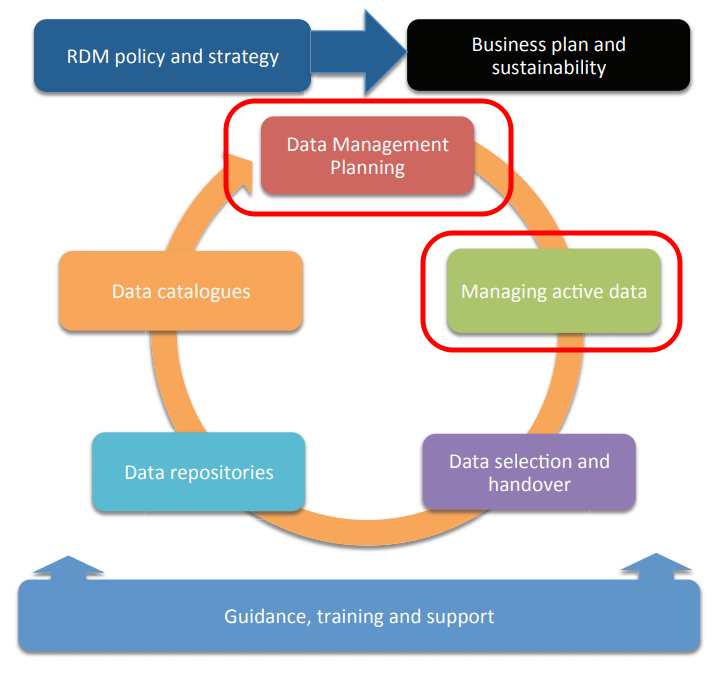
人手不足,以資料管理「自動化」因應
空氣盒子感測儀器的設立,緣自陳伶志研究員、中央研究院環境變遷研究中心龍世俊研究員共同主持的氣候變遷永續主題研究計畫,一開始僅在臺灣設立 20 多個感測點位。2015 年計畫結束後,陳伶志與 LASS 社群(開源公益環境感測網路)合作推出「開源空氣感測」方案,獲得社會廣泛的關注與支持,短短一個月就增加 100 多個感測點位,不到一年便增至 1000 多個點位。
陳伶志坦言,超過 1000 個點位後,研究資料的收取與釋出開始面臨諸多挑戰,包括收取到的資料如何即時同步、校正與整合,以及如何維持資料釋出的時效與穩定。「一開始反正資料來了就收,也沒有想到會做這麼大,直到我們進資料的速度大於處理資料的速度,我們才意識到收取資料和提供資料的服務,這兩項應該是分開的。尤其空氣盒子的資料特色是即時性,很多人會有各種不同的資料需求,例如即時資料、歷史資料、某一區的資料、每小時的平均值等。如果要從前端、資料、可視化全部處理,又要提供資料的對外服務,就必須找出幾個模板,透過可複製的模式最小化我們的負擔。」
陳伶志強調,「自動化」一定要做到,因為這影響到將來維持資料生產與使用的時間成本、人力成本等不穩定因素,「一開始要先想清楚研究資料本身的特色、價值,還有你的研究資料預期達到什麼樣的表現或成效。另外,要能夠彈性地去運用現有的資源,包括一些開源的工具、穩定的網路。我們的經驗是要把整個流程自動化、分段去處理——如果要改一個東西的時候,只需要把中間一個簡單的功能抽換掉。模組化做的很徹底,會是個好處。」
資料品質取決於資料的應用方式
隨著感測站點的增多,除了加重人力、時間成本的負擔,研究資料的有效性、穩定度也面臨挑戰。在研究資料收取的過程中,隨著參與人數增多,愈有可能出現資料品質雜亂、不穩定的情況,「感測站點需要裝在室外,量到的數值在鄰近區域通常會差不多,但有些參與者會把儀器裝在室內,可能就是有裝在室內、香爐上方,所以我們會看到一堆綠色中出現幾個紫色。」
「這些事情刺激了我們對異常偵測演算法的改善,開始針對每個感測器進行評分和標籤,去區分感測器可能出現的異常情況,例如被裝在室內、被裝在污染源旁邊等。同時我們也釋出了異常偵測演算法、標籤資料的方法,希望其他研究者也可以回過頭來驗證我們的計算結果。」陳伶志強調,空氣盒子計畫不只是為了自己的研究而去收取資料,更重視資料「時效性」可能為其他研究者帶來的研究價值。
「對我們 AirBox 來說,我們希望大家覺得這個研究計畫也是他的研究計畫!」空氣盒子的資料需要兼具快速與準確的性質,透過公開的資料校正方法、定義校正語言、每天更新的校正公式及參數,空氣盒子已經可以「夠好但非最好」地執行感測點位的資料異常偵測,甚至空氣品質預測。
陳伶志以「最佳空氣品質的路徑導航」應用為例,指出最佳空氣品質的路徑規劃,需要使用機器學習來進行預測,使用機器學習的挑戰在於需要花很多時間訓練機器,「全台灣我們有 3000 台、 4000 台感測器,可是我只有一台主機是要怎麼去訓練 (train) 呢?如果你要用很好、很準的方法就會花很長的時間,但是這樣未來一小時的預測結果,卻可能要花上半小時才給出答案,這就沒有意義啦!所以我們挑戰用一分鐘跑 3000 多個站,分區分開訓練,準確度稍微下降一點,但在可接受的範圍內。」這套應用已能成功規劃出從某處移動到另一地點時,一條當時空氣狀況最舒適、最乾淨的路徑。
讓研究資料在生產端與使用端,形成可持續的循環
提到「動態資料管理」的經驗,陳伶志指出「機器可讀」(machine readable)是台灣研究者較容易忽略的面向。例如空氣盒子的合作夥伴就曾在「日期」欄目使用中文的幾月幾日星期幾,或是在「裝置編號」欄目使用中文字為索引。「我覺得資料開放的指標,一個是我們自己會不會去用,另一個是國外會不會來用;如果一欄資料中、英夾雜的話,國外可能不會來用的。而且中文或英文的分開使用其實只是多一道工,具體做法包括將欄目區分為 names 以及 Chinese names 兩欄等等。」
在資料生產端的研究者,經常沒有意識到他生產出來的資料集,會對其他研究者造成「可取用性」的困擾,而這些小細節往往會造成研究資料的生產與使用無法形成一個循環。陳伶志分享空氣盒子以 API 形式釋出研究資料的現況,目前使用 2 台 Google Cloud 虛擬機器進行研究資料管理,其中一台專門作為收集資料的資料庫平台,另一台則專門提供大家網頁服務與下載資料使用,「我們空氣盒子的網站還有各種視覺化服務,就是用我們的 API 去做出來的。因為我們先生產 API,然後我們的網站去呼叫 API,所以等於是說我第一關就先驗證過這 API 是可用的。」
陳伶志建議研究者釋出研究資料的同時,也應釋出對資料格式的指引,或是 API 相對應的使用方法,「需要讓其他人知道這些研究資料長什麼樣子,自己也可以去試試看,用自己提供的方法能不能抓出自己想要的資料、抓出來的資料長什麼樣子。」陳伶志也提醒,「向後相容性」 (backward compatibility) 的問題需要特別留意,「比如說我們去接環保署的資料做校正,有時候因為他們改了一個東西,資料就會忽然不見。我們現在是使用 SwaggerHub API,去搭配 NGINX URL Rewrite,這樣可以確保當我改 API 的時候,可覆寫成 1.0 或 1.1 或 1.2 的版本,所以我釋出的 API 網址都是永遠有效的。」
研究資料永久保存需在機構的層級進行
與多數研究者相同,面對研究資料永久保存的議題,陳伶志也是且戰且走,「最近我有在想以後要怎麼辦,因為資料量越來越大,我也不知道要放哪裡,頂多就是再放另一台 NAS,可是一樣有連網路的話,被駭客入侵的風險還是一樣的,而且我現在的那台 NAS 萬一再被入侵的話,就完蛋了!」
陳伶志指出,空氣盒子用來存放研究資料的 NAS 曾被勒索軟體加密資料,雖然主因是人為因素忘記關閉防火牆,且資料有備份所以損失不大。資料的永久保存需要耗費愈來愈多的機器設備、人力維護成本,對空氣盒子來說是個不小的負擔。陳伶志呼籲臺灣學術機構效法美國哈佛大學創設的社會科學資料庫 Harvard Dataverse,透過組成研究資料庫的策略聯盟,共同分擔研究資料永久保存的責任,「研究計畫案結束後,研究資料的永久保存好像只有機構有長期的人力去做,期待自己有能量的單位可以來幫忙研究資料的保存或是管理。」
註釋及參考資料
- 若想評估研究資料管理規劃的完整程度,可以參考英國資料策展中心 (Digital Curation Centre) 發布的資料管理計畫檢核表;該表歸納出八個面向,分別為行政資訊 (Administrative Data) 、資料蒐集 (Data Collection) 、資料說明文件 (Documentation and Metadata) 、倫理與法律準則 (Ethics and Legal Compliance) 、資料儲存與備份 (Storage and Backup) 、選擇需永久保存的資料 (Selection and Preservation) 、資料分享 (Data Sharing) 、資料管理責任 (Responsibilities and Resources) ,可協助研究者在研究開始前,透過八個面向的思考,讓研究即將產生出的資料,得以發揮出最大的潛能。可見:https://www.dcc.ac.uk/sites/default/files/documents/resource/DMP/DMP_Checklist_2013.pdf。